Nội dung bài viết
© 2026 AI VIET NAM. All rights reserved.
Tác giả: Tuệ Thư (AIO2024), Đình Thắng (TA)
Keywords: mô hình học sâu, học AI online, phân loại văn bản
Text Classification (phân loại văn bản) là một bài toán quan trọng trong Xử lý Ngôn ngữ Tự nhiên (Natural Language Processing), nhằm gán nhãn hoặc phân loại văn bản vào các nhóm được xác định trước. Ứng dụng của Text Classification rất đa dạng, có thể kể đến như:

Trong bài toán Text Classification, ta cần chuyển đổi dữ liệu văn bản thành dạng số trước khi đưa vào mạng nơ-ron để học và phân loại. Quá trình này thường bao gồm nhiều bước, từ tiền xử lý dữ liệu, ánh xạ văn bản sang không gian vector, đến huấn luyện mô hình để tối ưu hóa khả năng phân loại. Hình 2 dưới đây minh họa quy trình đơn giản của bài toán này, bao gồm ba bước chính:
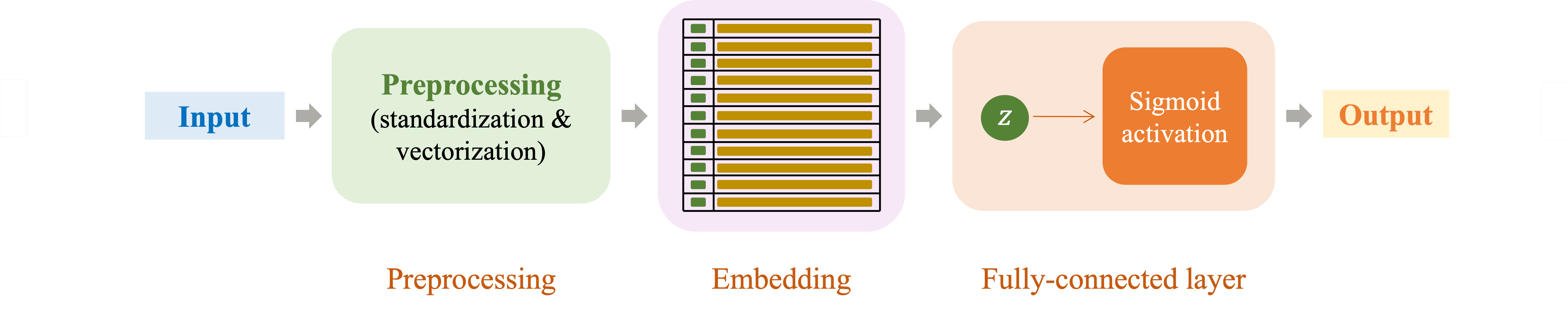
Đây là bước tiền xử lý dữ liệu, giúp chuẩn bị văn bản đầu vào cho quá trình xử lý tiếp theo. Quá trình này bao gồm các công đoạn sau:
Mã hóa các chỉ số thành vector có ý nghĩa, giúp biểu diễn ngữ nghĩa của văn bản trong không gian đa chiều, nơi mỗi vector mang nhiều thông tin về ngữ cảnh, mối quan hệ và các đặc trưng của từ hoặc câu.
Các vector embedding sẽ được đưa vào fully-connected layer để trích xuất đặc trưng, sau đó qua một hàm kích hoạt để tạo đầu ra. Trong hình 2, hàm kích hoạt Sigmoid được sử dụng để chuẩn hóa đầu ra về khoảng (0,1), biểu thị xác suất của một lớp trong phân loại nhị phân. Softmax cũng có thể được sử dụng để chuẩn hóa đầu ra thành một phân phối xác suất, trong đó tổng các xác suất bằng 1. Vì vậy, Softmax thường được dùng cho phân loại đa lớp, giúp mô hình hóa xác suất giữa nhiều nhãn và chọn nhãn có xác suất cao nhất.
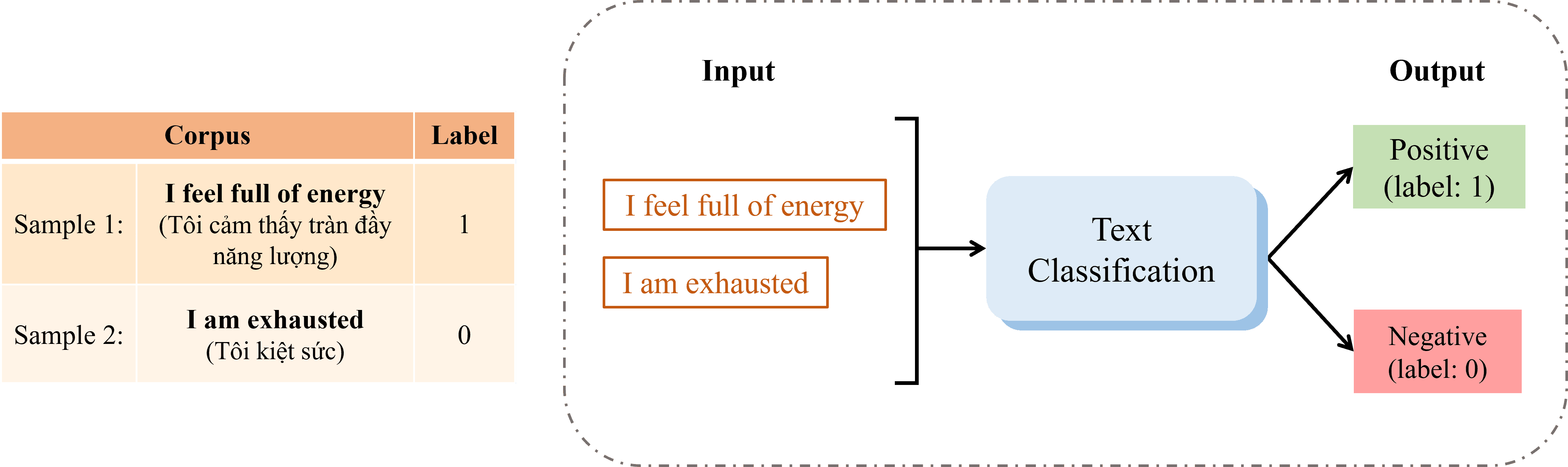
Trong phần này, chúng ta sẽ thực hiện một ví dụ (hình 3) để hiểu rõ từng bước giải quyết bài toán Text Classification.
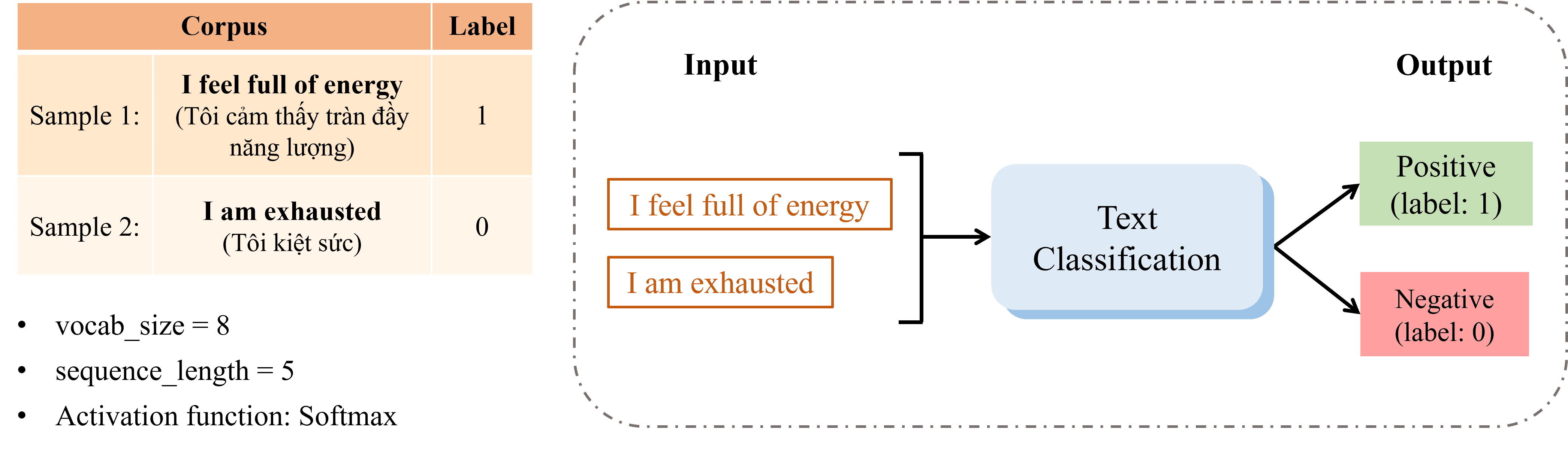
Mô tả đề bài: Cho đầu vào gồm hai câu, mỗi câu được gán nhãn (label) tương ứng:
Với vocab_size = 8, sequence_length = 5 và hàm kích hoạt Softmax, hãy phân loại hai câu đã cho vào hai nhóm Positive hoặc Negative dựa trên nội dung của chúng.
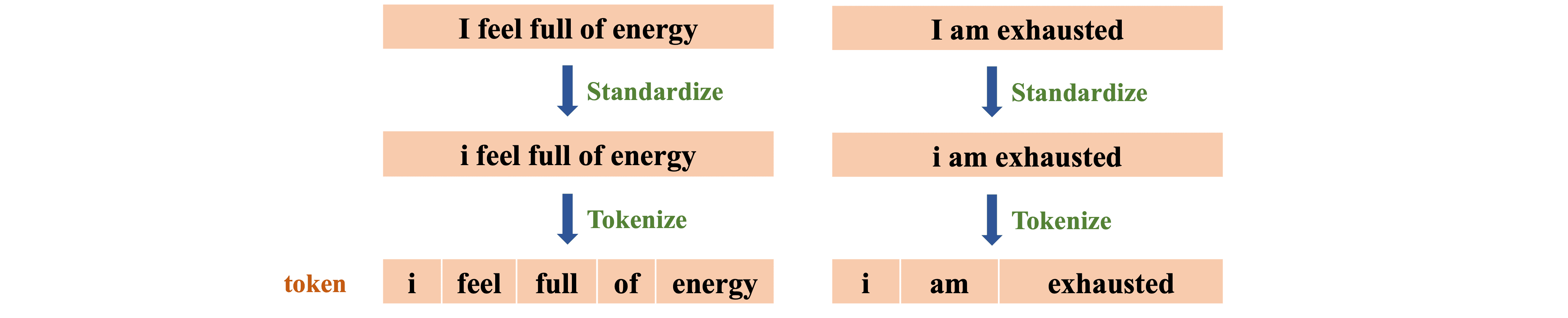
(1) Standardization & Tokenization: Chuyển tất cả chữ cái thành chữ thường, sau đó tách từ (word-level tokenization) dựa trên khoảng trắng (hình 4)
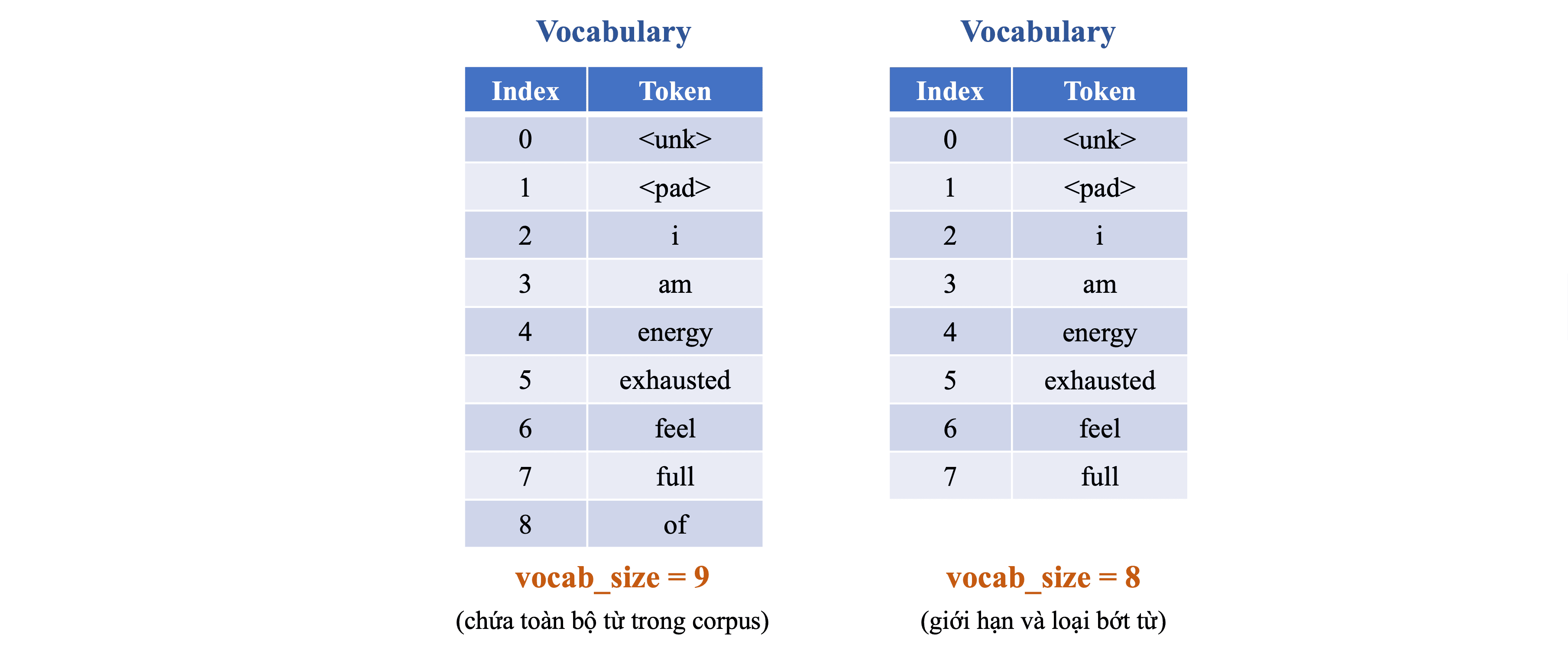
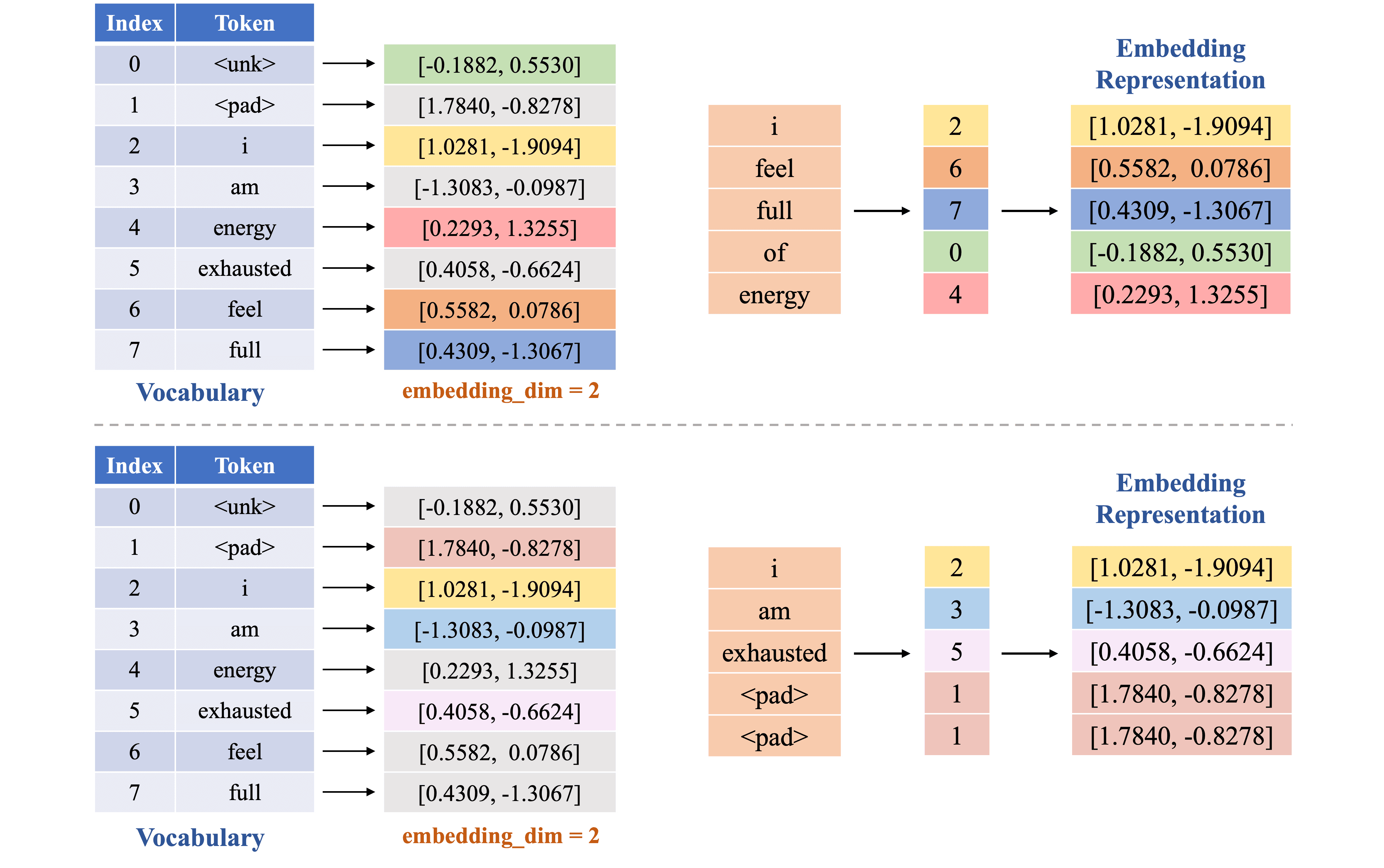
(2) Building Vocabulary: Xác định danh sách các từ duy nhất xuất hiện và gán một chỉ số duy nhất cho mỗi từ, tạo ra danh sách từ vựng (vocabulary) với \texttt{vocab_size = 8}, bao gồm cả các token đặc biệt như
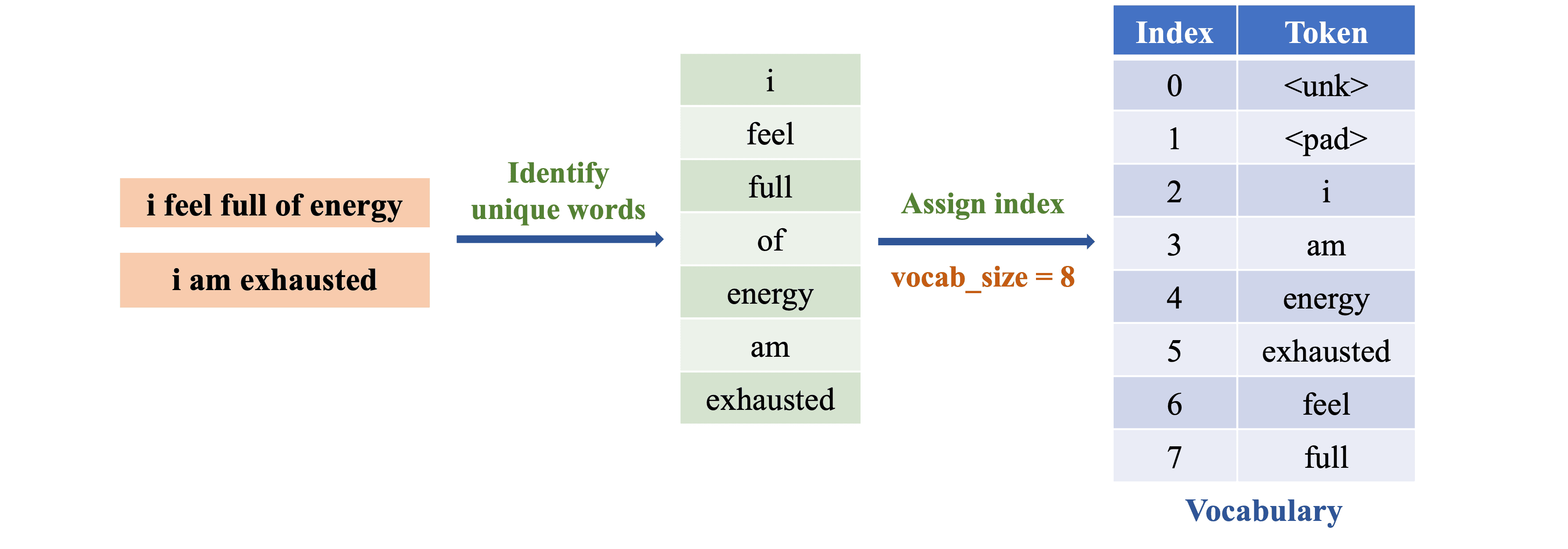
Khi xây dựng danh sách từ vựng, cần chú ý đến:
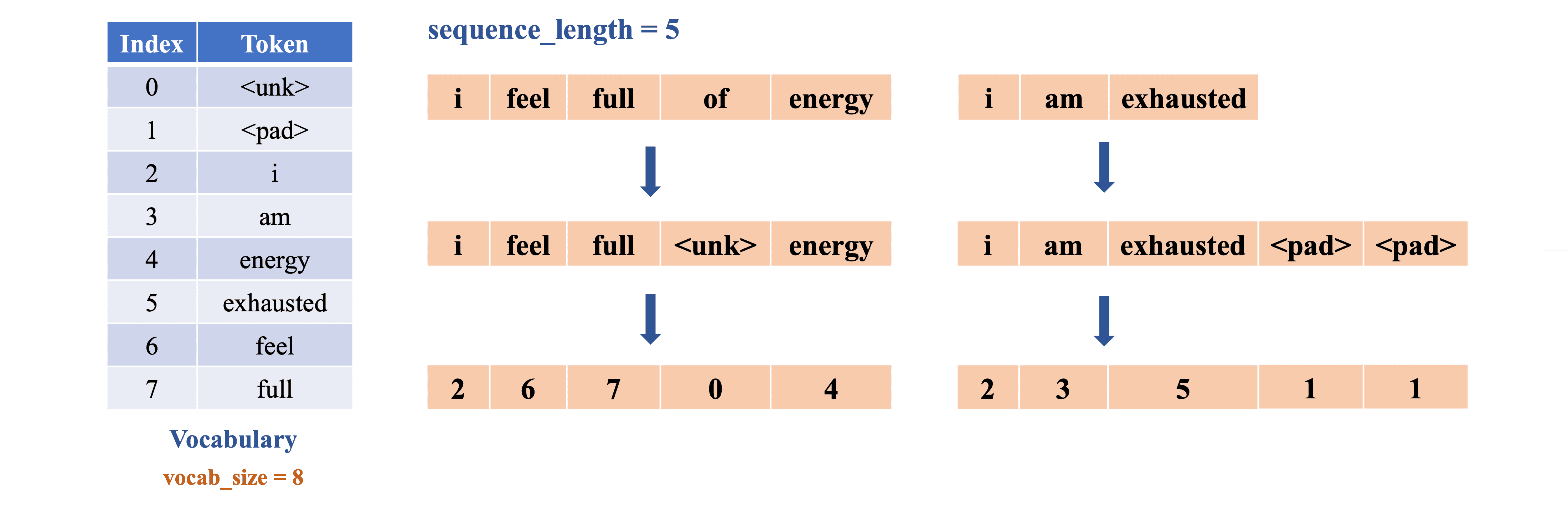
(3) Vectorization: Mỗi token trong từng sample được ánh xạ thành một số nguyên, chính là vị trí (index) tương ứng trong danh sách từ vựng, kết hợp với sequence_length = 5, cụ thể như sau:

Do đó:
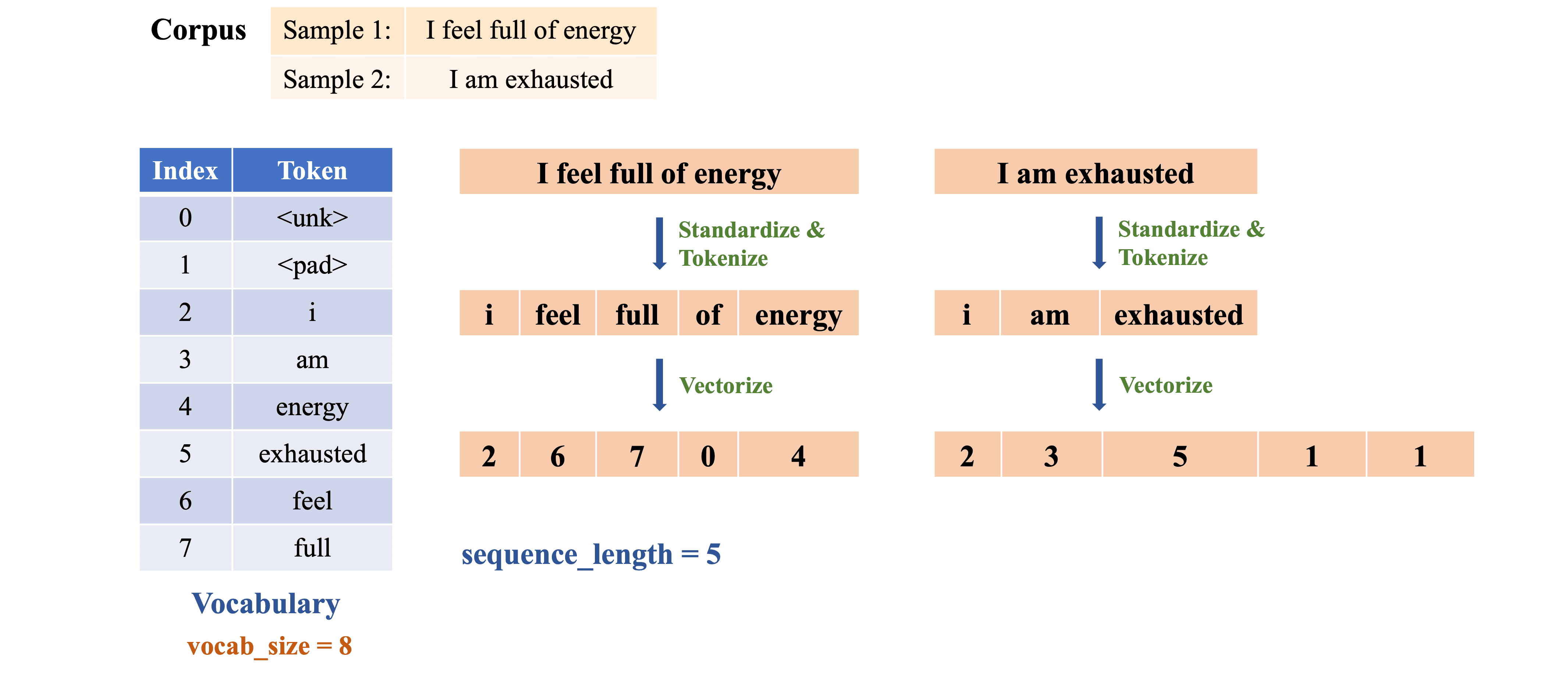
Hình 9 dưới đây tóm tắt lại toàn bộ quá trình Preprocessing qua từng công đoạn. Sau bước này, ta thu được chuỗi các token được ánh xạ thành các số nguyên, sẵn sàng cho bước tiếp theo.
Sau khi thực hiện Vectorization, chuỗi các số nguyên thu được vẫn chưa đủ đặc trưng và chưa đủ riêng để đại diện cho từng từ. Ví dụ, số 2 đơn thuần không đủ để diễn đạt ý nghĩa của từ "i" hay mối quan hệ giữa các từ trong câu. Do đó, ta cần một cách biểu diễn tốt hơn, giúp thể hiện rõ đặc trưng và ngữ nghĩa của từ.
Embedding là một phương pháp phổ biến để giải quyết vấn đề này, bên cạnh các cách tiếp cận khác như One-Hot Encoding, BoW (Bag-of-Words) hay TF-IDF, và hiện được xem là phương pháp biểu diễn hiệu quả nhất.
Embedding được biểu diễn dưới dạng một ma trận nhúng (embedding matrix) có kích thước (vocab_size, embedding_dim), trong đó mỗi token được ánh xạ thành một vector có embedding_dim chiều, giúp thể hiện đặc trưng và mối quan hệ ngữ nghĩa tốt hơn so với số nguyên đơn thuần.
Trong ví dụ này, ta sử dụng một embedding matrix với embedding_dim = 2 để đơn giản hóa quá trình tính toán với các giá trị trong ma trận được khởi tạo ngẫu nhiên (hình 10).
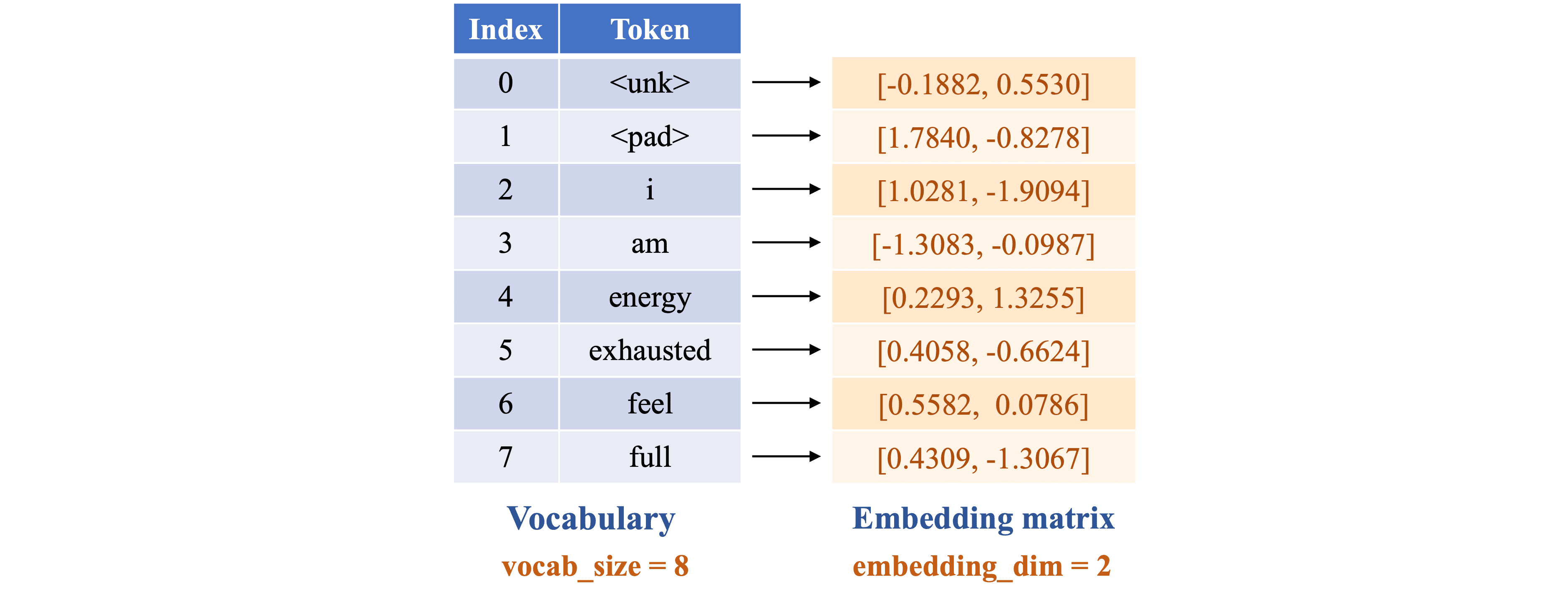
Hình 11 dưới đây minh họa quá trình ánh xạ token thành vector embedding dùng embedding matrix. Sau khi thực hiện bước Embedding, mỗi token ánh xạ thành một vector embedding có chiều bằng 2. Ví dụ, 'i' được ánh xạ thành vector [1.0281, -1.9094].
Sau khi hoàn tất bước Preprocessing và Embedding, ta có quy trình xử lý bài toán Text Classification được minh họa với sample 1 như sau (trong bước này, các tính toán sẽ được thực hiện trên sample 1 và được lặp lại tương tự cho sample 2):
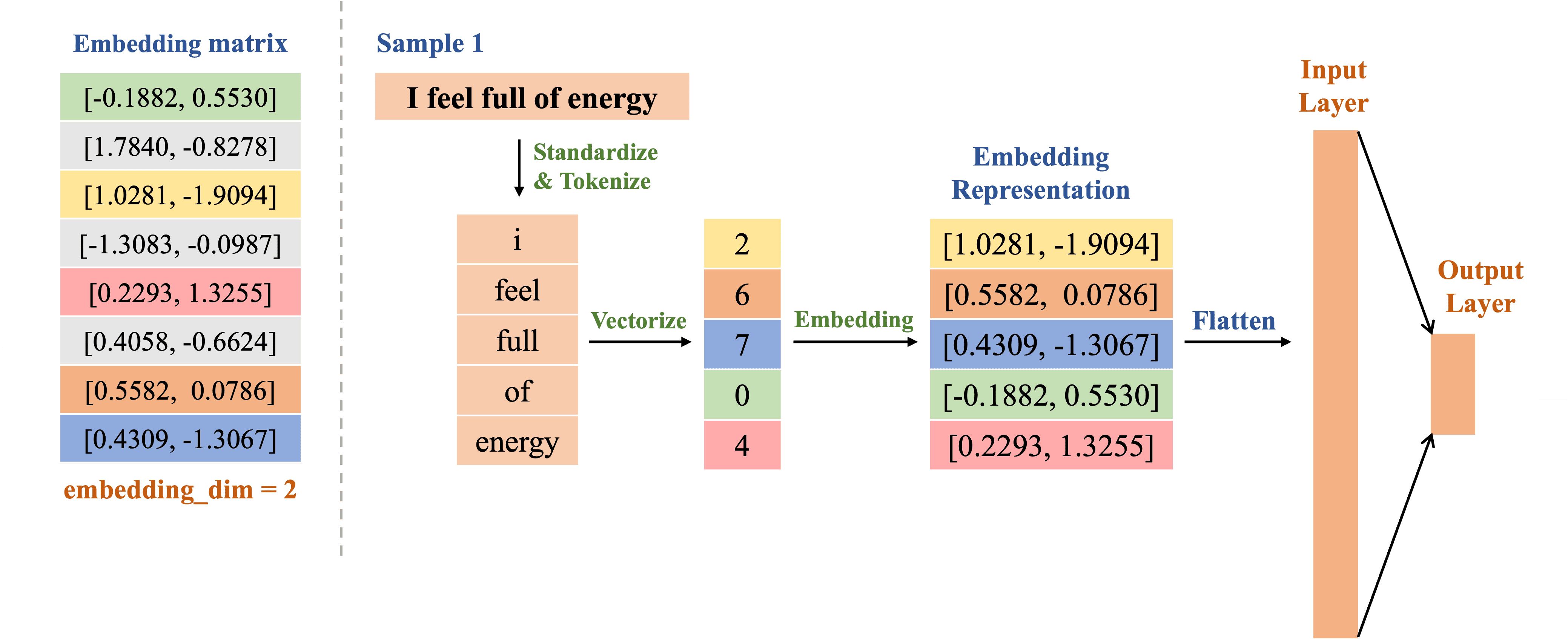
Dựa vào hình 12, cho đến thời điểm hiện tại, sample 1 đã được chuẩn hóa, tách thành các token và ánh xạ thành số nguyên dựa trên danh sách từ vựng. Tiếp theo, các số nguyên này được tra cứu trong embedding matrix để tạo thành embedding representation, biểu diễn đặc trưng của sample trước khi đưa vào fully-connected layer để xử lý.
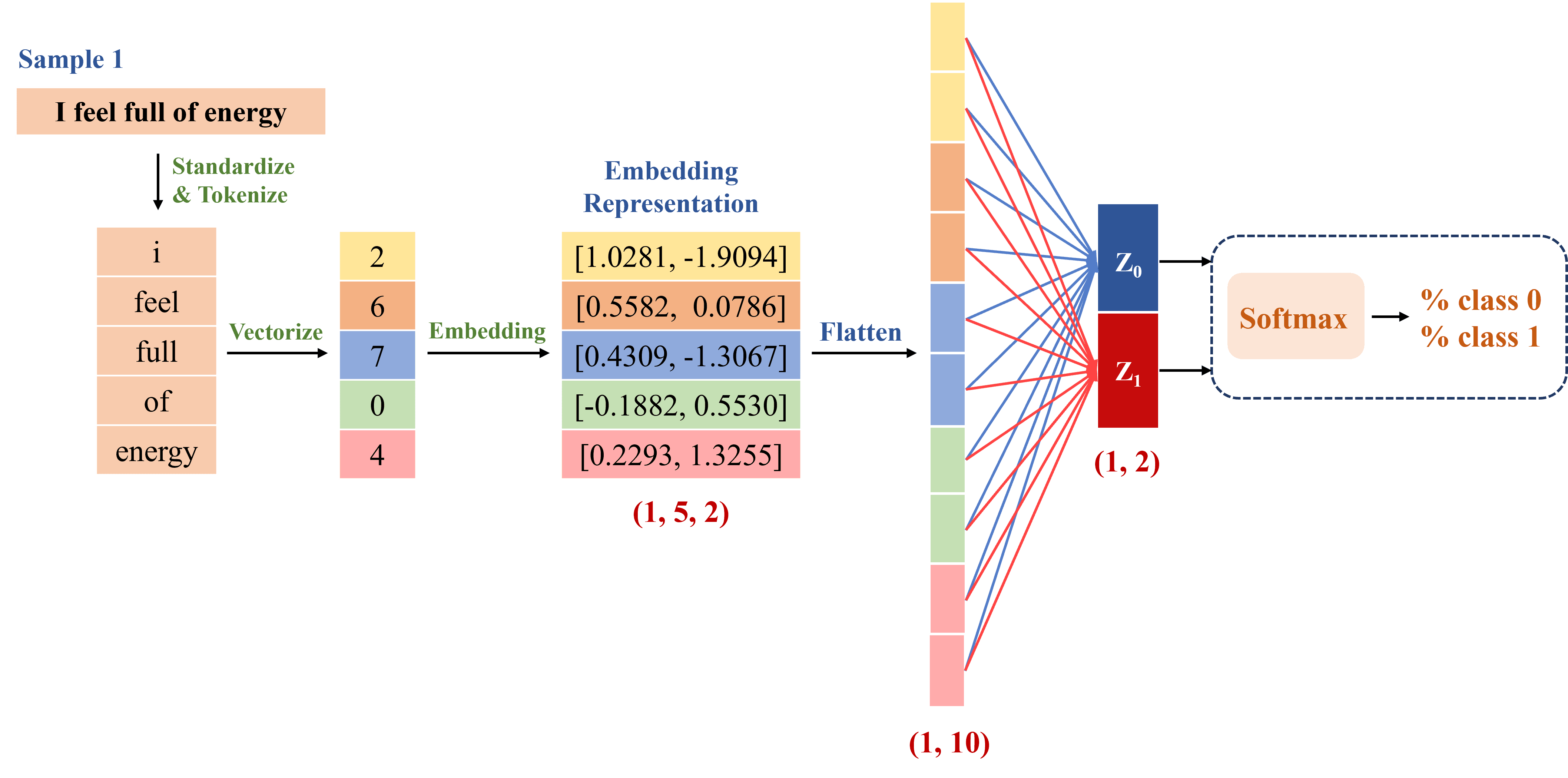
Để phù hợp với đầu vào của fully-connected layer, embedding representation cần được flatten, giúp điều chỉnh shape ban đầu từ (batch_size, sequence_length, embedding_dim) thành (batch_size, sequence_length × embedding_dim), trong đó:
Đối với ví dụ chúng ta thực hiện, embedding representation ban đầu có shape (1, 5, 2), tương ứng với batch_size = 1 (xử lý một sample tại một thời điểm), sequence_length = 5 (độ dài chuỗi sau khi tokenized), và embedding_dim = 2 (số chiều của vector embedding). Sau khi được flatten, nó trở thành đầu vào có shape (1, 10), nghĩa là một vector gồm 10 giá trị và sẵn sàng để đưa vào fully-connected layer.
Trong ví dụ này, đầu vào được biến đổi qua fully-connected layer theo công thức: , trong đó:
Với bài toán phân loại nhị phân, cụ thể trong ví dụ này là xác định câu có ý nghĩa tích cực hay tiêu cực, ta có output_dim = 2, tương ứng với hai giá trị và . Do đó, đầu ra cuối cùng có shape (1, 2), biểu diễn xác suất câu thuộc từng nhãn sau khi áp dụng hàm kích hoạt Softmax.
Dưới đây, chúng ta sẽ thực hiện cụ thể các phép tính trong fully-connected layer với đầu vào (tương ứng với sample 1) sau khi đã được flatten, cùng với các giá trị của trọng số và bias như sau:
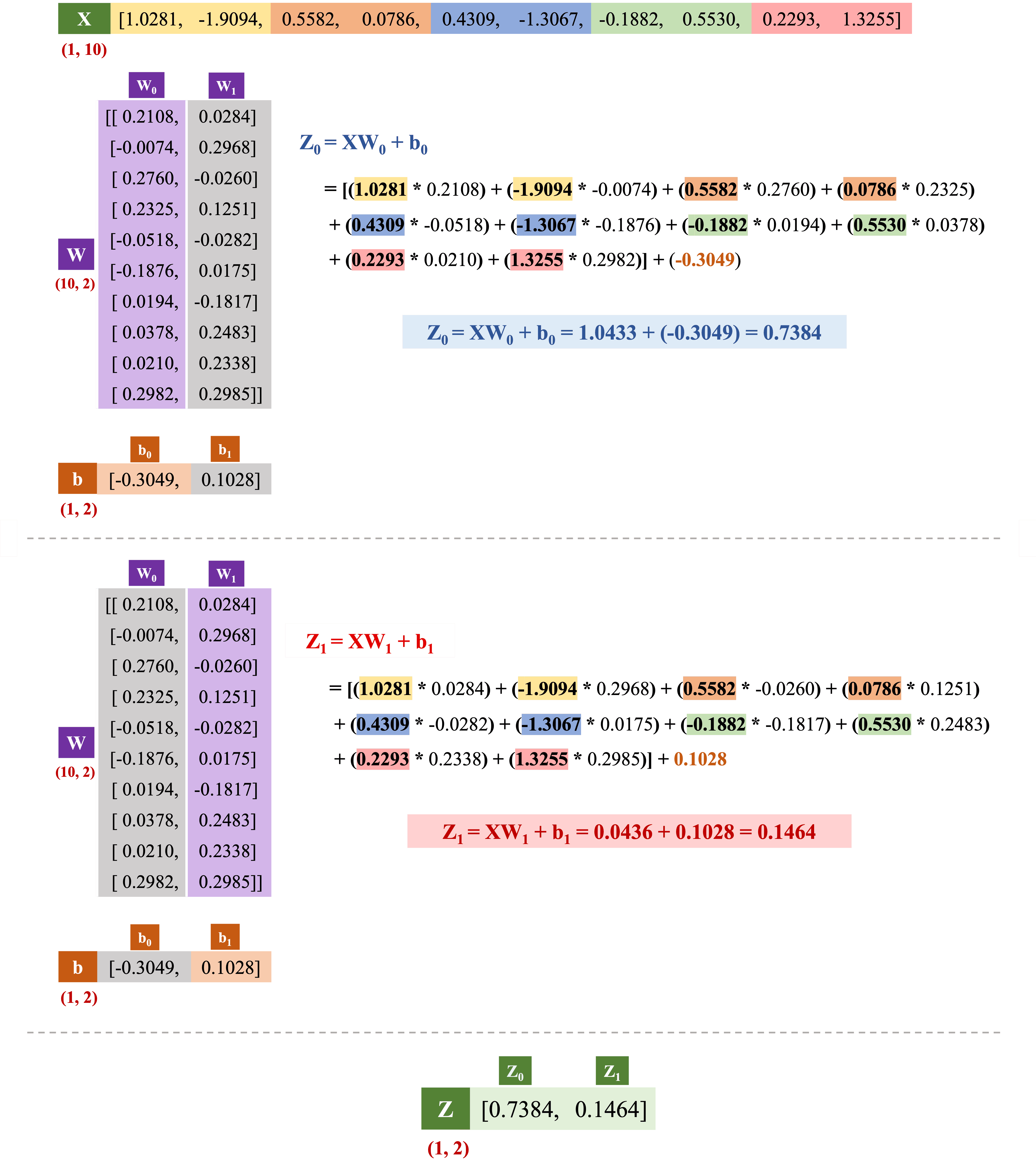
Hình 14 minh họa quá trình tính toán trong fully-connected layer. Cụ thể, được tính bằng cách lấy từng phần tử của nhân với từng phần tử tương ứng trong rồi cộng tổng lại (tính tích vô hướng (dot product) giữa và ), sau đó cộng thêm . Tương tự, là tích vô hướng giữa và cộng thêm .
Đầu ra sau khi tính toán được đưa qua hàm \texttt{Softmax} để chuyển đổi thành phân phối xác suất. Quá trình này giúp biểu diễn xác suất thuộc từng nhãn, từ đó giúp đưa ra quyết định gán nhãn tích cực hay tiêu cực cho sample.
Sau khi áp dụng Softmax, các giá trị và được chuyển đổi thành xác suất, đảm bảo tổng của chúng bằng 1. Như minh họa trong hình 15, xác suất dự đoán cho nhãn Negative (0) là 0.6438, trong khi xác suất cho nhãn Positive (1) là 0.3562. Điều này cho thấy mẫu đầu vào có khả năng cao hơn thuộc Negative (0).

Để đánh giá mức độ chính xác của dự đoán so với nhãn thực tế, ta sử dụng hàm mất mát Cross Entropy. Hàm này giúp đo lường sai lệch giữa phân phối xác suất dự đoán và nhãn thực, từ đó hướng dẫn mô hình cập nhật trọng số nhằm cải thiện độ chính xác trong các lần huấn luyện tiếp theo. Hàm mất mát Cross Entropy được định nghĩa như sau: trong đó:
Hình 16 dưới đây minh họa quá trình tính toán hàm mất mát Cross Entropy, với sample 1 "I feel full of energy" được gán nhãn 1 (Positive), tương ứng với = [0, 1] và có = [0.6438, 0.3562] sau khi qua hàm Softmax.

Với các giá trị và như trong hình 16, công thức Cross Entropy được áp dụng để đo lường mức độ sai lệch giữa dự đoán và nhãn thực tế. Kết quả thu được giá trị mất mát , phản ánh rằng dự đoán chưa khớp hoàn toàn với nhãn mong muốn.
Để giảm mất mát, ta dùng Stochastic Gradient Descent (SGD) để cập nhật tham số bằng cách tính gradient và điều chỉnh theo hướng giảm nhanh nhất. Hệ số học (learning rate) quyết định tốc độ cập nhật trọng số, bias và embedding matrix. Nếu embedding matrix được khởi tạo ngẫu nhiên, cần cập nhật để cải thiện khả năng biểu diễn; ngược lại, nếu embedding matrix đã đủ tốt, ta có thể giữ nguyên. Trong ví dụ này, do embedding matrix được khởi tạo ngẫu nhiên, việc cập nhật là cần thiết.
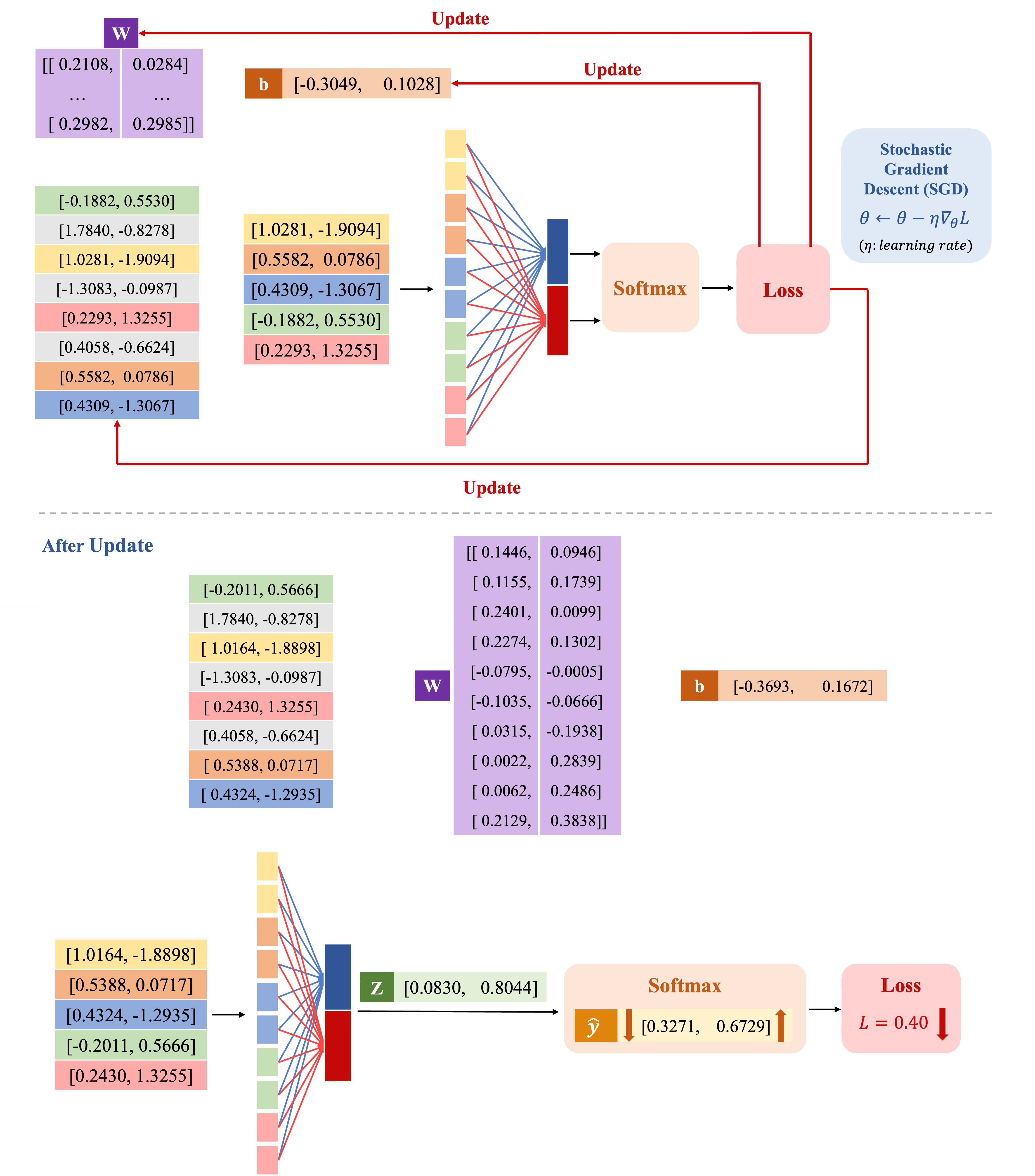
Sau khi cập nhật các tham số (hình 17), giá trị trọng số, bias và embedding matrix đã thay đổi theo hướng tối ưu hơn. Khi sử dụng các giá trị mới này để tính toán lại , sau đó áp dụng hàm Softmax, ta thu được xác suất dự đoán mới: xác suất của lớp đầu tiên giảm xuống 0.3271, trong khi xác suất của lớp thứ hai tăng lên 0.6729. Kết quả này cho thấy mô hình đang điều chỉnh để dự đoán chính xác hơn. Đồng thời, giá trị mất mát = 0.40 đã giảm so với trước khi cập nhật, phản ánh rằng quá trình tối ưu hóa đang diễn ra hiệu quả.
Trong phần này, chúng ta sẽ triển khai lại các bước tính toán đã thực hiện ở phần trước dưới dạng lập trình, nhằm kiểm chứng kết quả và quan sát quá trình xử lý một cách trực quan hơn.
Import library Đầu tiên, chúng ta sẽ import các thư viện cần thiết để xử lý dữ liệu và xây dựng mô hình.
import torch import torch.nn as nn from tokenizers import Tokenizer from tokenizers.models import WordLevel from tokenizers.trainers import WordLevelTrainer from tokenizers.pre_tokenizers import Whitespace
Preprocessing
corpus = [ "I feel full of energy", "I am exhausted" ] # 0: negative - 1: positive labels = [1, 0] # Define the max vocabulary size and sequence length vocab_size = 8 sequence_length = 5
Tokenization
Đoạn code dưới đây khởi tạo một tokenizer WordLevel, trong đó mỗi từ sẽ được ánh xạ thành một chỉ số riêng biệt sau khi xây dựng danh sách từ vựng. \texttt{tokenizer} được thiết lập để tách từ dựa trên khoảng trắng, nghĩa là mỗi từ được phân biệt nhờ dấu cách giữa chúng. Bên cạnh đó, nếu chuỗi ngắn hơn sequence_length, tokenizer sẽ thêm token
# Define tokenizer tokenizer = Tokenizer(WordLevel()) tokenizer.pre_tokenizer = Whitespace() tokenizer.enable_padding(pad_id=1, pad_token="<pad>", length=sequence_length) tokenizer.enable_truncation(max_length=sequence_length)
Building Vocabulary
Phần này xây dựng vocabulary từ tập dữ liệu bằng cách tạo một bộ huấn luyện trainer quy định số lượng từ tối đa trong danh sách từ vựng và bổ sung các token đặc biệt unk và pad. Tiếp theo, tokenizer sẽ lặp qua corpus, tách từ và học danh sách từ vựng. Kết quả thu được là một vocabulary dùng để mã hóa văn bản.
# Train the tokenizer trainer = WordLevelTrainer(vocab_size=vocab_size, special_tokens=["<unk>", "<pad>"]) tokenizer.train_from_iterator(corpus, trainer)
Vectorization
Đoạn code này chuyển văn bản thành dạng số bằng cách token hóa và ánh xạ từng từ thành chỉ số. Hàm vectorize nhận một câu đầu vào, sử dụng tokenizer để mã hóa và trả về tensor chứa các chỉ số tương ứng. Sau đó, mỗi câu trong corpus được xử lý bằng vectorize và lưu vào danh sách corpus_ids.
# Tokenize and numericalize the samples def vectorize(sentence, tokenizer): output = tokenizer.encode(sentence) return torch.tensor(output.ids, dtype=torch.long) # Vectorize the samples corpus_ids = [] for sentence in corpus: corpus_ids.append(vectorize(sentence, tokenizer)) # "I feel full of energy" --> [2, 6, 7, 0, 4] # "I am exhausted" --> [2, 3, 5, 1, 1]
Embedding
Tiến hành khởi tạo embedding matrix, sau đó ánh xạ các câu vào không gian nhúng. Kết quả thu được embedding representation có shape (1, 5, 2).
# With vocab_size = 8, define embedding dimension (2) embedding_dim = 2 embedding = nn.Embedding(vocab_size, embedding_dim) input_1 = torch.tensor([[2, 6, 7, 0, 4]], dtype=torch.long) label_1 = torch.tensor([1], dtype=torch.long) embedded_output_1 = embedding(input_1) input_2 = torch.tensor([[2, 3, 5, 1, 1]], dtype=torch.long) label_2 = torch.tensor([0], dtype=torch.long) embedded_output_2 = embedding(input_2) # Shape of embedded_output_1 and embedded_output_2: torch.Size([1, 5, 2])
Fully-connected layer
Lớp nn.Flatten chuyển đổi đầu vào từ dạng (batch_size, sequence_length, embedding_dim) thành (batch_size, sequence_length * embedding_dim).
# Flatten flatten = nn.Flatten() flattened_output_1 = flatten(embedded_output_1) # Shape of flattened_output_1: torch.Size([1, 10])
Tiếp theo, lớp nn.Linear(10, 2) đóng vai trò thực hiện phép biến đổi tuyến tính với 10 đầu vào và 2 đầu ra. Trong PyTorch, khi khởi tạo lớp nn.Linear, các tham số trọng số và bias được tự động khởi tạo ngẫu nhiên. Mô hình được xây dựng gồm ba phần: embedding để chuyển đổi từ vựng thành vector nhúng, flatten để làm phẳng đầu ra, và fc để biến đổi đặc trưng.
Lưu ý: Lớp nn.Linear trong PyTorch có cách tổ chức trọng số khác so với phép nhân ma trận thông thường. Khi khởi tạo nn.Linear(in_features, out_features), PyTorch sẽ tự động khởi tạo ma trận trọng số với kích thước (out_features, in_features), nghĩa là (2, 10) trong trường hợp này. Vì vậy, nếu tự khởi tạo trọng số, cần chú ý sử dụng đúng kích thước này.
# Fully connected (FC) layer: 10 input features and 2 output features fc = nn.Linear(10, 2) # Define a simple model with embedding, flattening, and FC transformation model = nn.Sequential(embedding, flatten, fc) output_sample_1 = model(input_1)
Hàm mất mát CrossEntropyLoss được sử dụng để đo độ chênh lệch giữa đầu ra của mô hình và nhãn thực tế. Trong PyTorch, CrossEntropyLoss đã bao gồm bước Softmax. Do đó, đầu vào của hàm mất mát là đầu ra trực tiếp từ mô hình (chưa qua Softmax).
# Calculate loss criterion = nn.CrossEntropyLoss() loss = criterion(output_sample_1, label_1) print(loss)
Thực hiện cập nhật trọng số mô hình bằng thuật toán tối ưu SGD với tốc độ học . Sau khi tính gradient thông qua loss.backward(), optimizer.step() sẽ cập nhật các tham số của mô hình.
# Update parameters with SGD optimizer = torch.optim.SGD(model.parameters(), lr=0.1) loss.backward() optimizer.step()
Sau đây là phần code đầy đủ cho bài phân loại dùng mô hình chứa một lớp linear:
from tokenizers import Tokenizer from tokenizers.models import WordLevel from tokenizers.trainers import WordLevelTrainer from tokenizers.pre_tokenizers import Whitespace import torch import torch.nn as nn # ================ data =================== corpus = [ "I feel full of energy", "I am exhausted" ] labels = [1, 0] # 0: negative - 1: positive vocab_size = 8 sequence_length = 5 # Initialize the tokenizer and define a trainer tokenizer = Tokenizer(WordLevel()) tokenizer.pre_tokenizer = Whitespace() tokenizer.enable_padding(pad_id=1, pad_token="<pad>", length=sequence_length) tokenizer.enable_truncation(max_length=sequence_length) # Train the tokenizer on your corpus trainer = WordLevelTrainer(vocab_size=vocab_size, special_tokens=["<unk>", "<pad>"]) tokenizer.train_from_iterator(corpus, trainer) # Tokenize and numericalize your samples def vectorize(sentence, tokenizer): output = tokenizer.encode(sentence) return torch.tensor(output.ids, dtype=torch.long) # Vectorize the samples corpus_ids = [] for sentence in corpus: corpus_ids.append(vectorize(sentence, tokenizer)) # Convert to tensor inputs = torch.stack(corpus_ids) labels = torch.tensor(labels, dtype=torch.long) # ================ model ================ embedding = nn.Embedding(vocab_size, 2) flatten = nn.Flatten() fc = nn.Linear(10, 2) model = nn.Sequential(embedding, flatten, fc) # ================ train ================ criterion = nn.CrossEntropyLoss() optimizer = torch.optim.SGD(model.parameters(), lr=0.1) for _ in range(50): optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # ================ verify ================ outputs = model(inputs) print(torch.softmax(outputs, axis=-1)) # tensor([[0.0194, 0.9806], # [0.9773, 0.0227]], grad_fn=<SoftmaxBackward0>)
----------------------------------------- Hết -----------------------------------------



