Recurrent Neural Networks (RNNs) là một kiểu mạng deep learning được thiết kế đặc biệt để xử lý và học từ dữ liệu tuần tự (sequential), ví dụ như văn bản (text), chuỗi thời gian (time-series), hay âm thanh (audio). Các mạng RNN nổi bật với khả năng lưu giữ thông tin từ các bước trước đó trong chuỗi, giúp chúng đặc biệt hữu ích trong các bài toán như phân tích ngôn ngữ tự nhiên và dự đoán chuỗi thời gian. Tuy nhiên, một hạn chế lớn của RNN là việc xử lý tuần tự: mô hình phải xử lý từng bước trong chuỗi theo thứ tự, dẫn đến thời gian huấn luyện chậm và khó khăn khi phải nắm bắt các mối quan hệ xa trong chuỗi dài.
Để khắc phục các hạn chế của RNN, Transformer đã được giới thiệu vào năm 2017, mang lại một bước tiến đột phá trong xử lý dữ liệu tuần tự. Điểm nổi bật của Transformer là cơ chế "self-attention", cho phép mô hình tập trung vào toàn bộ chuỗi dữ liệu đồng thời, thay vì xử lý tuần tự như RNN. Với self-attention, Transformer có thể tính toán mối liên hệ giữa các phần trong chuỗi một cách trực tiếp và song song, từ đó cải thiện hiệu suất và khả năng học các mối quan hệ dài hạn.
Hình 2: Kiến trúc mạng tổng quan của Transformer. Nguồn: Link.
Transformer hoạt động dựa trên kiến trúc encoder-decoder, trong đó:
Encoder (bên trái Hình 2): Nhận dữ liệu đầu vào, biểu diễn nó dưới dạng vector embedding, và áp dụng self-attention để tìm mối liên hệ giữa các phần tử trong chuỗi dữ liệu.
Decoder (bên phải Hình 2): Sử dụng kết quả từ encoder, kết hợp với cơ chế attention để tạo ra đầu ra, chẳng hạn như câu dịch hoặc văn bản tóm tắt.
Cơ chế self-attention là trung tâm của Transformer. Thay vì chỉ tập trung vào phần dữ liệu ngay trước hoặc sau phần tử hiện tại (như trong RNN), self-attention cho phép mô hình "nhìn" toàn bộ chuỗi và quyết định mức độ quan trọng của từng phần tử trong việc dự đoán kết quả. Điều này giúp Transformer dễ dàng học được mối quan hệ giữa các phần tử cách xa nhau trong chuỗi.
Một ưu điểm lớn khác của Transformer là khả năng xử lý song song, nhờ không phụ thuộc vào tính tuần tự như RNN. Điều này giúp giảm đáng kể thời gian huấn luyện khi làm việc với dữ liệu lớn. Chính nhờ những ưu điểm này, Transformer đã nhanh chóng trở thành tiêu chuẩn trong các bài toán xử lý ngôn ngữ tự nhiên, như dịch máy, tóm tắt văn bản, và trả lời câu hỏi. Tuy vậy, mặc dù Transformer là một kiến trúc cực kỳ mạnh mẽ và tiềm năng, song thời điểm nghiên cứu ban đầu chỉ thực hiện trên dữ liệu văn bản. Điều này đã thôi thúc các nhà nghiên cứu tìm cách áp dụng Transformer cho các kiểu dữ liệu khác, đặc biệt là dữ liệu hình ảnh. Trong số các công trình đã được thực hiện, Vision Transformer (ViT) là một điểm nổi bật.
Ý tưởng cốt lõi của ViT là chuyển đổi hình ảnh thành một chuỗi các vùng ảnh nhỏ, gọi là "patch", tương tự như cách một câu được chia thành các từ trong ngôn ngữ. Sau khi chia hình ảnh thành các patch, mỗi patch được chuyển đổi tuyến tính (linear projection) thành một vector biểu diễn (embedding), tương tự như cách các token embedding được sử dụng trong Transformer gốc. Các vector này sau đó được kết hợp với thông tin vị trí (positional encoding) để tạo thành một chuỗi các embedding, đóng vai trò là đầu vào cho Transformer.
Khi đã có chuỗi các vector embedding này, ViT áp dụng gần như tương tự các bước tính toán như trong encoder của Transformer. Cụ thể, ViT sử dụng cơ chế self-attention để tính toán mối liên hệ giữa các patch trong toàn bộ bức ảnh, cho phép mô hình hiểu được các đặc trưng không gian và mối quan hệ giữa các vùng khác nhau trong hình ảnh. Quá trình này giúp ViT tận dụng sức mạnh tính toán song song và khả năng học các mối quan hệ dài hạn của Transformer, đồng thời thích ứng hoàn hảo với dữ liệu hình ảnh. Với cách tiếp cận này, ViT không chỉ kế thừa sức mạnh từ Transformer mà còn mở ra một hướng đi mới trong xử lý hình ảnh, nơi dữ liệu hình ảnh được biểu diễn và phân tích theo cách giống như dữ liệu ngôn ngữ. Đây chính là bước tiến quan trọng, đặt nền móng cho việc ứng dụng Transformer vào các lĩnh vực thị giác máy tính.
Hình 3: Kỹ thuật patching hướng đến việc chia ảnh thành các "patch", là các vùng ảnh có kích thước bằng nhau.
Để hiểu rõ cách hoạt động của ViT, chúng ta sẽ tìm hiểu từng bước xử lý mà ViT cần thực hiện trong một lần forward dữ liệu đầu vào để lấy kết quả dự đoán. Theo đó, với pipeline xử lý tổng quát của ViT, như được minh họa trong (Hình 1), chúng ta sẽ khám phá cách xử lý dữ liệu cho một ảnh và một batch ảnh.
Trong bước đầu tiên của pipeline Vision Transformer (ViT), chúng ta cần định nghĩa rõ cấu trúc của ảnh đầu vào và cách chia ảnh thành các patch nhỏ. Một ảnh đơn sẽ được biểu diễn dưới dạng tensor với kích thước H×W×C, trong đó H,W,C lần lượt là chiều cao, chiều rộng và số kênh (channel).
Đối với batch ảnh, tensor sẽ có kích thước B×H×W×C, với B là số lượng ảnh trong batch. Kích thước patch được quy định là P×P, và tổng số lượng patch N trên mỗi ảnh được tính theo công thức:
N=P2H⋅W.
Như vậy, bước đầu tiên sẽ nhận đầu vào (input) là một ảnh hoặc một batch ảnh. Với đầu vào là một ảnh đơn, ảnh được biểu diễn dưới dạng tensor I∈RH×W×C, trong đó H, W, và C lần lượt là chiều cao, chiều rộng và số kênh (channel) của ảnh. Đối với batch ảnh, đầu vào được biểu diễn dưới dạng tensor Ibatch∈RB×H×W×C, với B là số lượng ảnh trong batch.
Kết quả đầu ra (output) của bước này là ảnh hoặc batch ảnh đã được xử lý, chia thành các patch nhỏ ở bước tiếp theo.
Bước 2 tiếp tục với việc chia tensor đầu vào I thành N patch nhỏ. Mỗi patch có kích thước P×P×C, và sau đó được làm phẳng (flatten) để chuyển thành một vector với chiều dài P2C. Quá trình này giúp tổ chức lại thông tin từ ảnh gốc dưới dạng các vector nhỏ hơn, chuẩn bị cho các bước xử lý tiếp theo. Đầu ra cho một ảnh được biểu diễn như sau:
Xpatch∈RN×(P2C).
Đối với batch ảnh Ibatch, quá trình này được áp dụng cho từng ảnh trong batch. Sau khi chia, batch ảnh được sắp xếp lại thành một tensor với kích thước:
Xpatch_batch∈RB×N×(P2C),
Bước 3 liên quan đến quá trình Patch Embedding, trong đó các patch được ánh xạ từ không gian RP2C sang không gian RD bằng cách sử dụng một tầng tuyến tính (Linear Layer). Quá trình này được thực hiện thông qua công thức chính, với WE∈R(P2C)×D là trọng số và bE∈RD là bias của tầng embedding:
E=Xpatch⋅WE+bE,
Đối với batch ảnh, công thức trên được áp dụng cho toàn bộ batch, cụ thể:
Ebatch=Xpatch_batch⋅WE+bE.
Đầu vào của bước này bao gồm tensor Xpatch∈RN×(P2C) đối với một ảnh và tensor Xpatch_batch∈RB×N×(P2C) đối với batch ảnh. Kết quả đầu ra là tensor E∈RN×D cho một ảnh và tensor Ebatch∈RB×N×D cho batch ảnh. Quá trình này đảm bảo rằng các patch đã được ánh xạ sang không gian mới để phù hợp với các bước tiếp theo trong pipeline Vision Transformer.
Hình 4: Biểu diễn Positional Encoding trên không gian vị trí và chiều sâu. Nguồn: Link.
Bước 4 tiếp tục bằng việc thêm thông tin về vị trí vào từng patch. Điều này được thực hiện bằng cách cộng thêm một vector mã hóa vị trí Epos vào tensor đầu vào E. Quá trình này được biểu diễn qua công thức:
Z0=E+Epos,
trong đó E∈RN×D là tensor đại diện cho các patch sau bước embedding, và Epos∈RN×D là vector mã hóa vị trí có cùng kích thước.
Đối với batch ảnh, cách làm tương tự được áp dụng trên toàn bộ batch. Công thức tổng quát cho batch ảnh được viết như sau:
Z0_batch=Ebatch+Epos,
với Ebatch∈RB×N×D là tensor đại diện cho các patch trong batch và Epos∈RN×D là vector mã hóa vị trí được áp dụng cho từng ảnh trong batch.
Bước 5 xử lý qua Transformer Encoder, bắt đầu bằng việc áp dụng Layer Normalization (LayerNorm) lên đầu vào. Với dữ liệu đầu vào Z0 cho một ảnh và Z0_batch cho batch ảnh, kết quả sau LayerNorm được tính như sau:
Z′0=LN(Z0),Z′0_batch=LN(Z0_batch).
Sau bước LayerNorm, Multi-Head Self-Attention (MSA) được thực hiện. Quá trình này bắt đầu bằng việc tính toán các tensor Query (Q), Key (K), và Value (V) cho từng head. Cụ thể, với một ảnh, chúng được tính như sau:
Hình 5: Minh họa về Layer Normalization. Nguồn: Link.
Cuối cùng, cho từng patch vector sau Multi-Head Self-Attention (MSA) đã được norm vào Multi-layer Perceptron (MLP). MLP trong cài đặt ở bài này sẽ bao gồm hai tầng tuyến tính (Linear Layers) được kết nối với nhau bởi hàm kích hoạt GELU. Kết quả sau khi qua MLP được cộng thêm residual từ đầu vào để tạo ra đầu ra cuối cùng. Công thức tổng quát cho một ảnh được viết như sau:
H=GELU(Z′1⋅W1+b1),Z2=H⋅W2+b2+Z1.
Đối với batch ảnh, quá trình này được thực hiện tương tự với công thức tổng quát là:
Z′1 là đầu ra đã chuẩn hóa từ bước MSA. Z′1_batch∈RB×N×D cho batch ảnh
W1 và W2 là ma trận trọng số của hai tầng tuyến tính.
b1 và b2 là bias của hai tầng tuyến tính.
GELU là hàm kích hoạt Gaussian Error Linear Unit.
Kết quả đầu ra lần lượt là tensor Z2∈RN×D cho một ảnh và Z2_batch∈RB×N×D cho batch ảnh. Quá trình này đảm bảo rằng mỗi patch vector được xử lý qua một mạng tuyến tính để tăng cường thông tin trước khi tiếp tục đến bước tiếp theo trong pipeline.
Về lý thuyết, Transformer Encoder với LayerNorm, Self-Attention, Residual Connection và MLP sẽ giúp đảm bảo thông tin trong các patch được xử lý hiệu quả, giữ lại các mối quan hệ quan trọng trong dữ liệu đầu vào. Ở cài đặt thực tế, ta có thể cài đặt sử dụng nhiều Encoder Block một cách tuần tự. Song trong bài này, ta sẽ chỉ quan tâm một Encoder Block.
Bước 6 tập trung vào việc trích xuất token đặc biệt [CLS] từ chuỗi các patch vector đã được xử lý trước đó. Token đặc biệt [CLS] được định nghĩa là hàng đầu tiên của ma trận đầu ra Z2. Đây là vector duy nhất đại diện cho toàn bộ thông tin từ các patch của hình ảnh và thường được sử dụng làm đầu vào cho các nhiệm vụ phân loại hoặc các bước xử lý tiếp theo trong pipeline. Công thức trích xuất như sau:
ZCLS=row1(Z2),
trong đó:
Z2∈RN×D là ma trận đầu ra sau khi đi qua Multi-Layer Perceptron (MLP).
ZCLS∈RD là vector đại diện duy nhất của token [CLS].
row1(Z2) biểu diễn hàng đầu tiên của ma trận Z2.
Đối với batch ảnh, quy trình này được áp dụng cho toàn bộ các ảnh trong batch, token [CLS] được lấy từ hàng đầu tiên của mỗi tensor trong batch Z2,batch. Công thức được biểu diễn như sau:
ZCLS, batch=slice(Z2,batch,axis=1,index=1),
trong đó:
Z2,batch∈RB×N×D là tensor đầu ra của batch ảnh, với B là số lượng ảnh trong batch.
ZCLS, batch∈RB×D là ma trận chứa token [CLS] của từng ảnh trong batch.
Hàm slice trích xuất hàng đầu tiên của mỗi tensor trong batch.
Kết quả của bước này là token [CLS] dưới dạng tensor ZCLS∈RD đối với một ảnh và ZCLS, batch∈RB×D đối với batch ảnh. Những token này được thiết kế để nắm giữ thông tin tổng quát nhất của ảnh hoặc batch ảnh, chuẩn bị cho các nhiệm vụ phân loại hoặc các bước xử lý tiếp theo trong pipeline.
Hình 6: So sánh giữa việc sử dụng kỹ thuật average pooling với token [CLS] (màu vàng).
Bước cuối cùng của pipeline là Classification Head, trong đó một MLP (Multi-Layer Perceptron) được sử dụng để ánh xạ token [CLS] thành các lớp phân loại. MLP bao gồm một hoặc nhiều tầng tuyến tính, cùng với hàm kích hoạt GELU, và kết thúc bằng việc áp dụng hàm Softmax để tính xác suất cho từng lớp.
Đầu tiên, token [CLS] được đưa vào tầng ẩn (Hidden Layer), với quá trình tính toán được biểu diễn như sau:
Hhidden=GELU(ZCLS⋅Whidden+bhidden),
với ZCLS∈RD là token đầu vào, Whidden và bhidden lần lượt là trọng số và bias của tầng ẩn. Đối với batch ảnh, công thức tương ứng là:
Đầu ra cuối cùng của pipeline là các xác suất Probabilities∈RC cho một ảnh và Probabilitiesbatch∈RB×C cho batch ảnh, trong đó C là số lớp phân loại. Kết quả này đại diện cho dự đoán của mô hình, hoàn thiện quá trình xử lý từ đầu vào đến đầu ra của Vision Transformer.
Thực hành
Dựa theo các công thức tổng quan đã đề cập phía trên trong quá trình forward của Vision Transformer (ViT), chúng ta sẽ thực hành chạy tay các bước trên sử dụng một ma trận nhỏ và đơn giản làm ảnh đầu vào ví dụ. Theo đó, ta sẽ định nghĩa một bức ảnh đầu vào dạng grayscale kích thước 4×4. Để áp dụng kiến trúc ViT, chúng ta cần phải đi qua một quá trình bao gồm 8 bước chính như trên pipeline, bao gồm: từ việc chuẩn bị dữ liệu đầu vào đến đầu ra cuối cùng qua đầu mạng (classification head). Sau đây, ta sẽ cùng đi qua tính toán cụ thể từng bước:
Hình 7: Minh họa quá trình chuyển đổi từ ảnh đầu vào thành các vector embedding trong Vision Transformer.
Định nghĩa ảnh đầu vào và kích thước patch
Giả sử bức ảnh đầu vào là một ma trận I có kích thước 4×4, I∈RH×W×C, với H, W, và C lần lượt là chiều cao, chiều rộng, và số kênh của ảnh.
I=15913261014371115481216
Chia ảnh thành các patch
Để xử lý ảnh đầu vào trong ViT, chúng ta cần chia ảnh thành các patch nhỏ hơn. Mỗi patch sẽ đóng vai trò là một token cho các bước xử lý tiếp theo. Kích thước mỗi patch có dạng P×P. Chọn kích thước P=2. Khi đó, số lượng patch sẽ được tính như sau:
N=P2H×W=2×24×4=4
Như vậy, ảnh đầu vào được chuyển đổi thành một chuỗi gồm 4 patch, mỗi patch được biểu diễn dưới dạng một vector trong không gian features. Cụ thể ta có patch 1 là [1, 2, 5, 6], patch 2 là [3, 4, 7, 8], patch 3 là [9, 10, 13, 14], patch 4 là [11, 12, 15, 16].
Sau khi reshape và làm phẳng từng patch, ma trận đầu ra Xpatch∈RN×(P2⋅C) chứa tất cả các patch có dạng là:
Ma trận Z0 đại diện cho embedding của các patch, sau khi đã được bổ sung thông tin về vị trí của từng patch. Ma trận này sẽ được sử dụng làm đầu vào cho bước tính toán Self-Attention.
Hình 8: Ảnh minh họa về phép Positional Encoding.
Transformer Encoder
Bước này thực hiện các phép tính trong một khối Transformer Encoder, gồm ba phần chính. Đầu tiên là Layer Normalization trước Multi-Head Self-Attention (MSA), bao gồm tính toán Query, Key, Value, Attention Scores, và Output. Tiếp theo ta sử dụng Residual Connection và Layer Normalization sau Attention và cuối cùng là thành phần Multi-layer Perceptron (MLP) để đưa ra dự đoán cuối cùng
Ta dùng công thức dưới đây để tính các ma trận (Q), (K), (V) cho cho Head 1:
Q(1)=Z′0⋅WQ(1),K(1)=Z′0⋅WK(1),V(1)=Z′0⋅WV(1).
Tương tự cho Head 2:
Q(2)=Z′0⋅WQ(2),K(2)=Z′0⋅WK(2),V(2)=Z′0⋅WV(2).
Q1=K1=V1 và Q2=K2=V2 có giá trị giống nhau nguyên nhân là do dữ liệu đầu vào Z′0 (sau chuẩn hóa) đồng nhất và trong các ma trận WQ, WK, WV không khác biệt đủ để tạo ra sự biến đổi đáng kể. Tuy nhiên đây chỉ là bài toán kiểm thử (toy example) nên không gây ra vấn đề lớn. Cần lưu ý là trong thực tế, khi dữ liệu và trọng số được học từ quá trình huấn luyện, Q,K,V sẽ khác nhau, giúp đảm bảo tính hiệu quả của Multi-Head Attention.
Tính trung bình (μi) và độ lệch chuẩn (σi) của từng hàng:
μ1=311.229+13.123+14.693=13.015,σ1=3(11.229−13.015)2+(13.123−13.015)2+(14.693−13.015)2≈1.416.
Tính tương tự cho các hàng khác:
μ2=18.515,σ2≈2.069;μ3=34.415,σ3≈4.027;μ4=39.915,σ4≈4.681.
Chuẩn hóa từng hàng:
Z1′[1,:]=σ1Z1[1,:]−μ1=1.416[11.22913.12314.693]−13.015=[−1.2610.0761.185].
Tương tự cho Z′1[2,:],Z′1[3,:],Z′1[4,:], ta được kết quả cuối cùng của Z′1.
Z1′=−1.261−1.250−1.238−1.2360.0760.0520.0270.0231.1851.1981.2111.213,Z1′∈R4×3.
Hình 9: Ảnh minh họa luồng tính toán trong một Transformer Encoder Block được sử dụng trong Vision Transformer. Trong đó: LN = LayerNorm, MSA = Multi-head Attention, MLP = Multi-layer Perceptron.
Input của bước này là ma trận Z2∈R4×3, đầu ra của bước 5.
Trong ViT, token [CLS] được định nghĩa là hàng đầu tiên của ma trận Z2, ký hiệu là ZCLS. Đây là vector duy nhất đại diện cho toàn bộ thông tin từ các patch và có thể được sử dụng làm đầu vào cho bước tiếp theo - bước đưa ra kết quả dự đoán (Classification Head).
Áp dụng công thức trích xuất:
ZCLS=row1(Z2)=[12.09414.48716.556]
Output của bước này là vector ZCLS∈R1×3, đại diện cho token [CLS]. Token [CLS] đóng vai trò là một đầu ra gọn nhẹ, tóm tắt toàn bộ thông tin học được từ các patch ảnh và là bước chuẩn bị cuối cùng trước khi thực hiện phân loại. Tính cô đọng của ZCLS giúp tăng hiệu quả trong các tác vụ phân loại, đồng thời giữ lại ngữ nghĩa chính yếu từ toàn bộ ảnh đầu vào.
Hình 10: Transformer Encoder hoàn chỉnh. Bên trong bao gồm một số lượng L các Encoder Block.
Classification Head (MLP Head)
Trong bước này, token [CLS] được đưa qua một mạng MLP (Multilayer Perceptron) để thực hiện tác vụ phân loại. Mạng MLP này bao gồm hai tầng tuyến tính (linear layers) và một hàm kích hoạt phi tuyến GELU ở giữa.
Vector đầu vào là ZCLS∈R1×3, được trích xuất từ bước 6:
ZCLS=[12.09414.48716.556]
7.1. Tầng tuyến tính đầu tiên: Ta có công thức như sau: H=GELU(ZCLS⋅Whidden+bhidden)
Với:
Kết quả cuối cùng của bước này là vector xác suất Poutput∈R1×2, đại diện cho khả năng mẫu đầu vào thuộc về từng lớp. Như vậy mạng MLP Head thực hiện chuyển đổi từ token [CLS] thành các xác suất phân loại cho từng lớp. Đây là bước cuối cùng trong mô hình Vision Transformer (ViT), nơi toàn bộ thông tin từ ảnh được chuyển thành đầu ra phục vụ các tác vụ phân loại cụ thể.
Hình 11: Từ ảnh đầu vào đến giá trị dự đoán nhận được từ ViT.
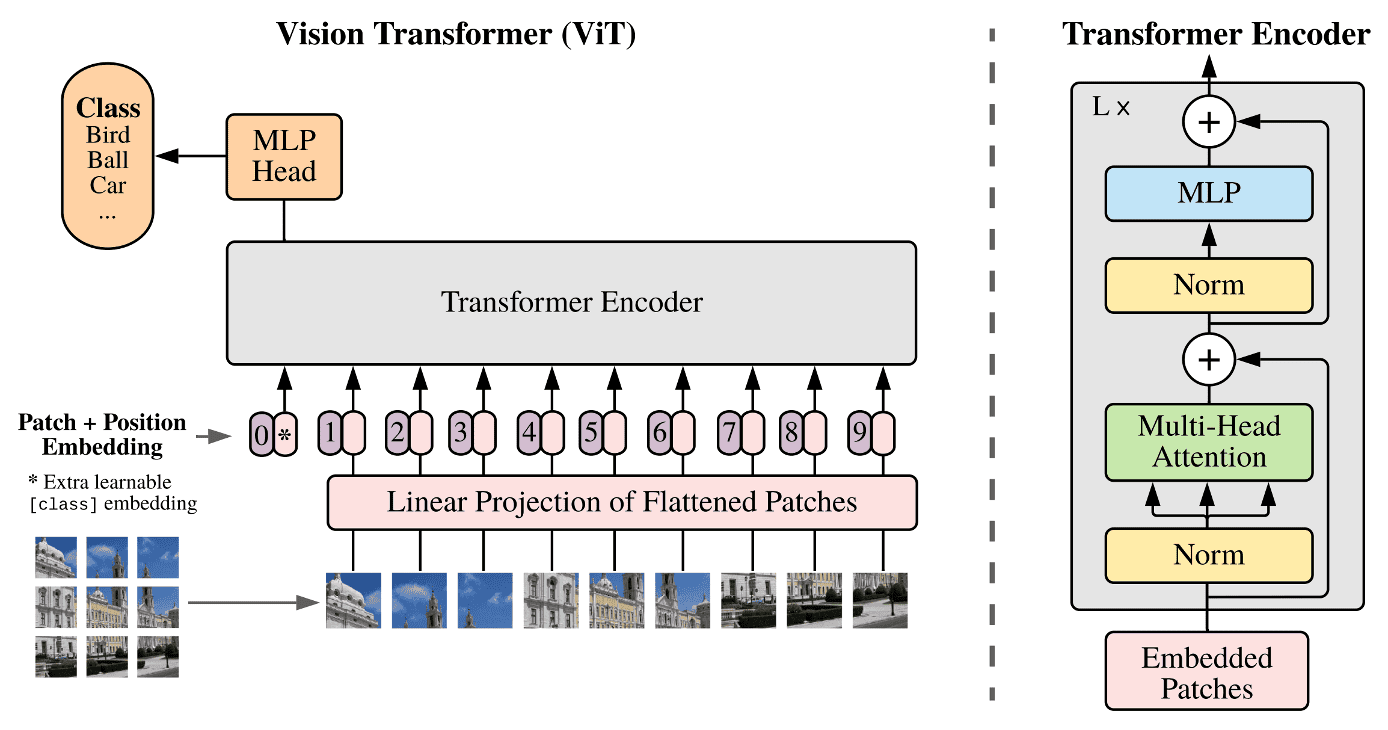 Hình 1: Kiến trúc tổng quan của ViT. Nguồn: Link.
Hình 1: Kiến trúc tổng quan của ViT. Nguồn: Link.
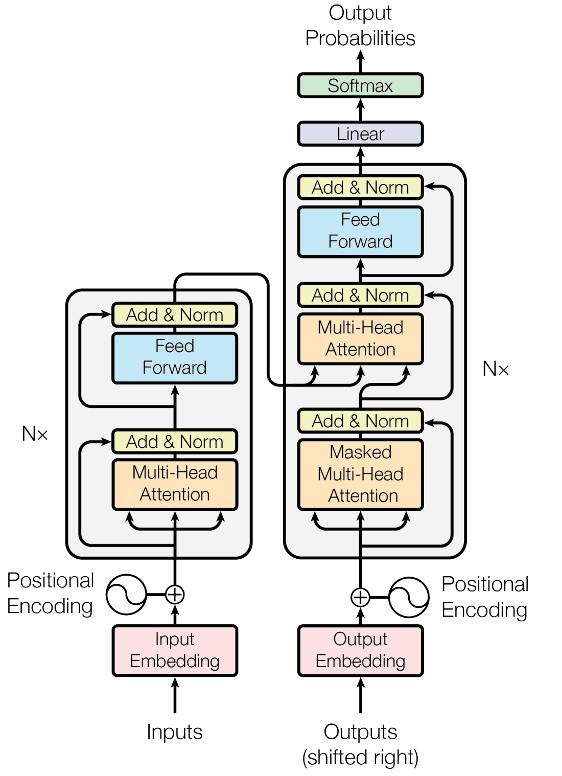 Hình 2: Kiến trúc mạng tổng quan của Transformer. Nguồn: Link.
Hình 2: Kiến trúc mạng tổng quan của Transformer. Nguồn: Link.
 Hình 3: Kỹ thuật patching hướng đến việc chia ảnh thành các "patch", là các vùng ảnh có kích thước bằng nhau.
Hình 3: Kỹ thuật patching hướng đến việc chia ảnh thành các "patch", là các vùng ảnh có kích thước bằng nhau.
 Hình 4: Biểu diễn Positional Encoding trên không gian vị trí và chiều sâu. Nguồn: Link.
Hình 4: Biểu diễn Positional Encoding trên không gian vị trí và chiều sâu. Nguồn: Link.
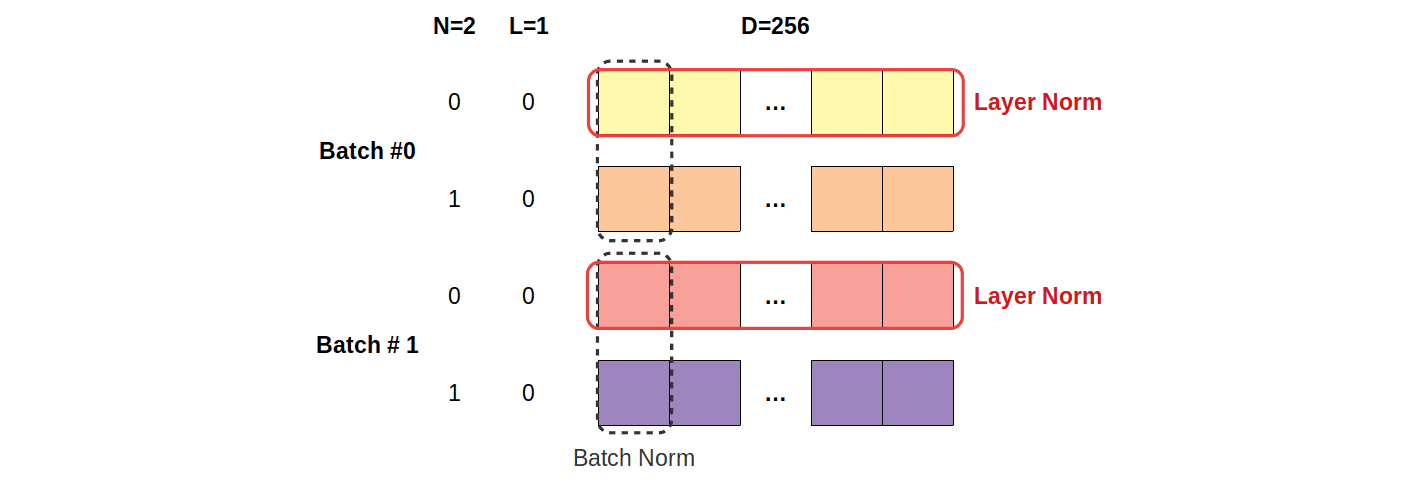 Hình 5: Minh họa về Layer Normalization. Nguồn: Link.
Hình 5: Minh họa về Layer Normalization. Nguồn: Link.
![So sánh giữa việc sử dụng kỹ thuật average pooling với token [CLS] (màu vàng).](https://cms.aivietnam.edu.vn/uploads/figure_07_0341833538.png) Hình 6: So sánh giữa việc sử dụng kỹ thuật average pooling với token [CLS] (màu vàng).
Hình 6: So sánh giữa việc sử dụng kỹ thuật average pooling với token [CLS] (màu vàng).
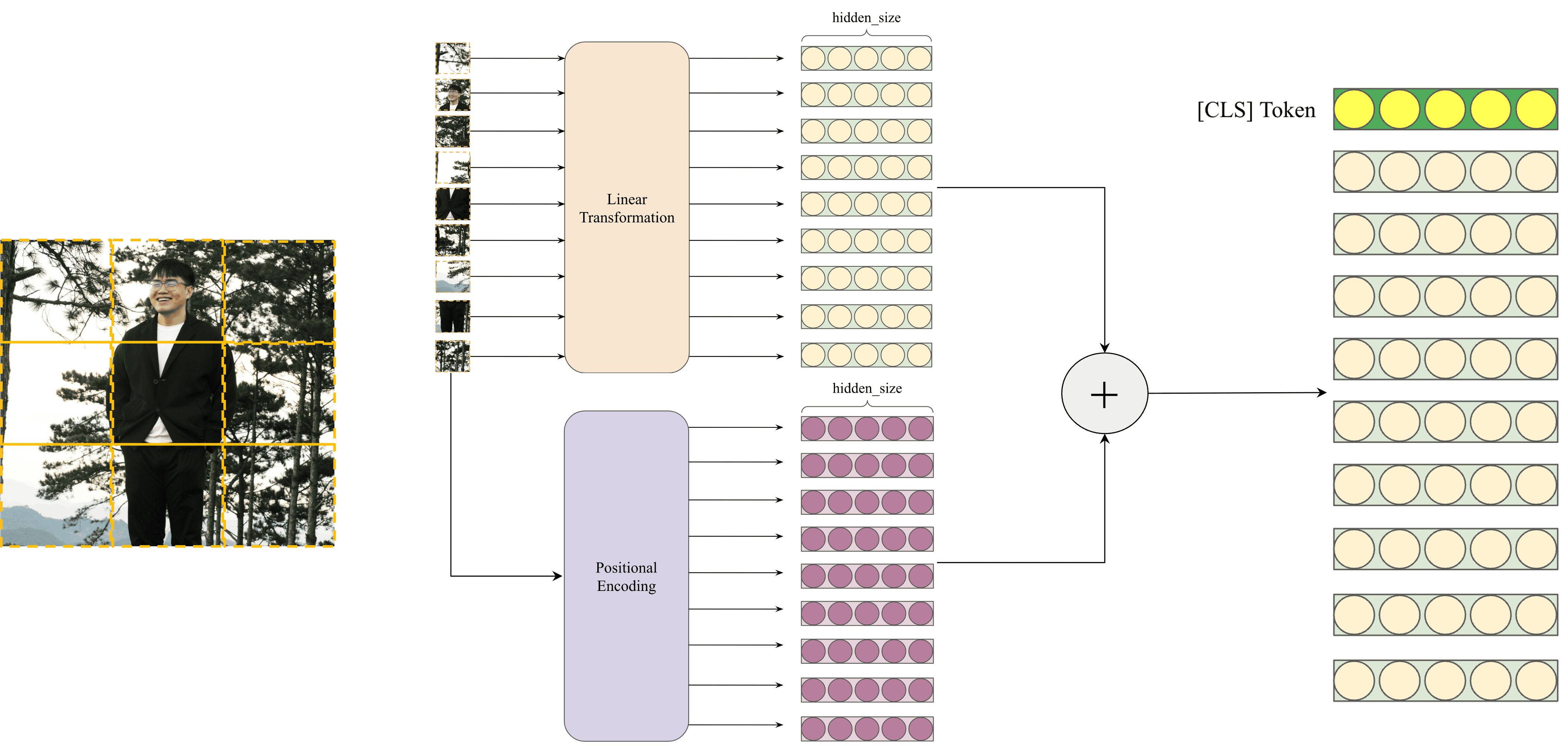 Hình 7: Minh họa quá trình chuyển đổi từ ảnh đầu vào thành các vector embedding trong Vision Transformer.
Hình 7: Minh họa quá trình chuyển đổi từ ảnh đầu vào thành các vector embedding trong Vision Transformer.
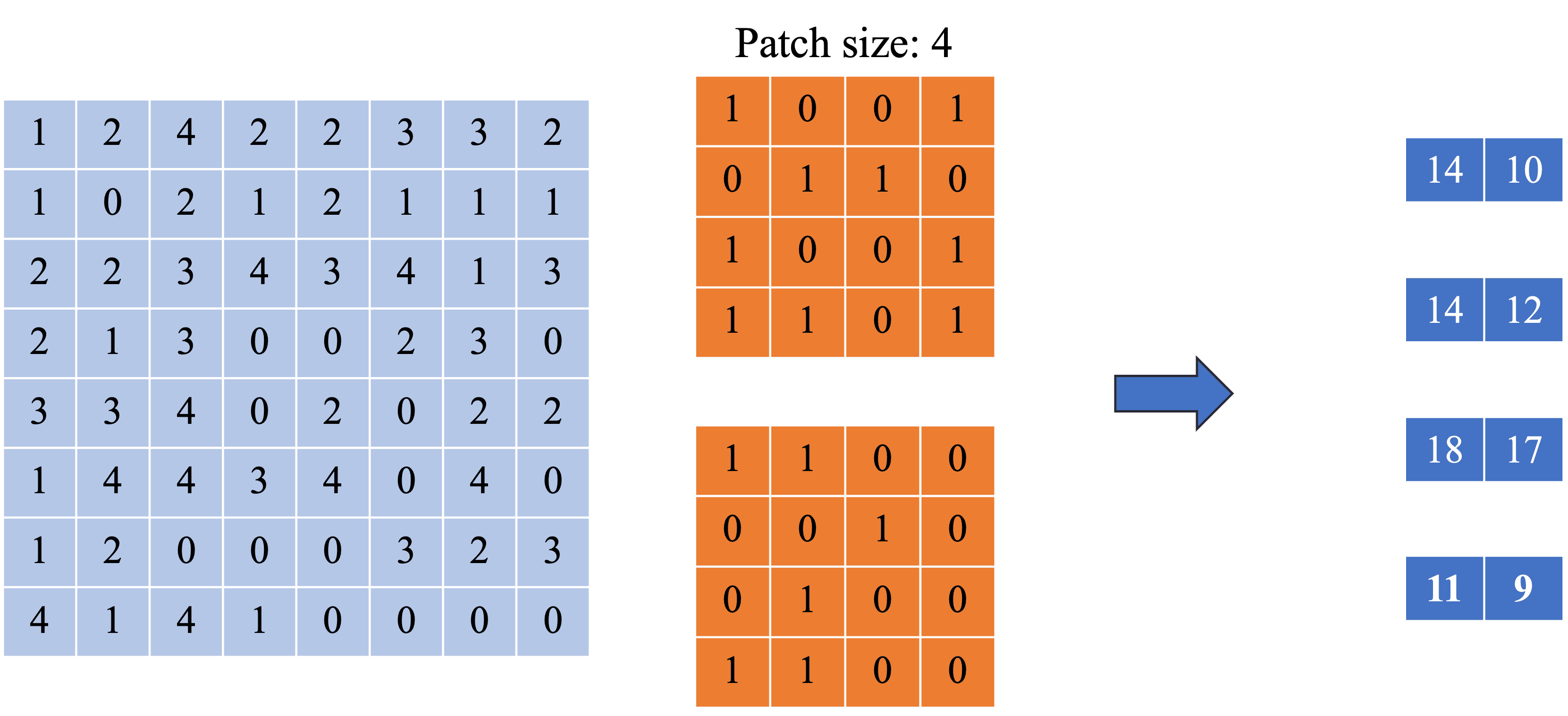 Hình 8: Ảnh minh họa về phép Positional Encoding.
Hình 8: Ảnh minh họa về phép Positional Encoding.
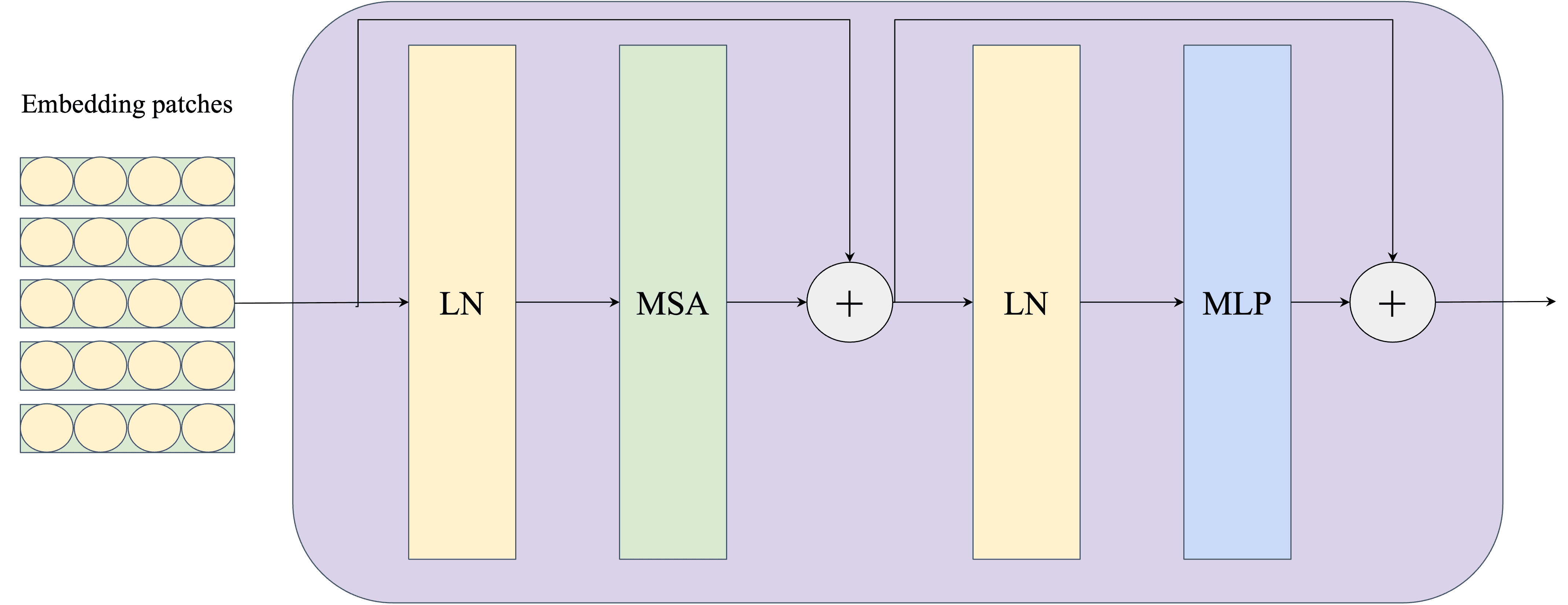 Hình 9: Ảnh minh họa luồng tính toán trong một Transformer Encoder Block được sử dụng trong Vision Transformer. Trong đó: LN = LayerNorm, MSA = Multi-head Attention, MLP = Multi-layer Perceptron.
Hình 9: Ảnh minh họa luồng tính toán trong một Transformer Encoder Block được sử dụng trong Vision Transformer. Trong đó: LN = LayerNorm, MSA = Multi-head Attention, MLP = Multi-layer Perceptron.
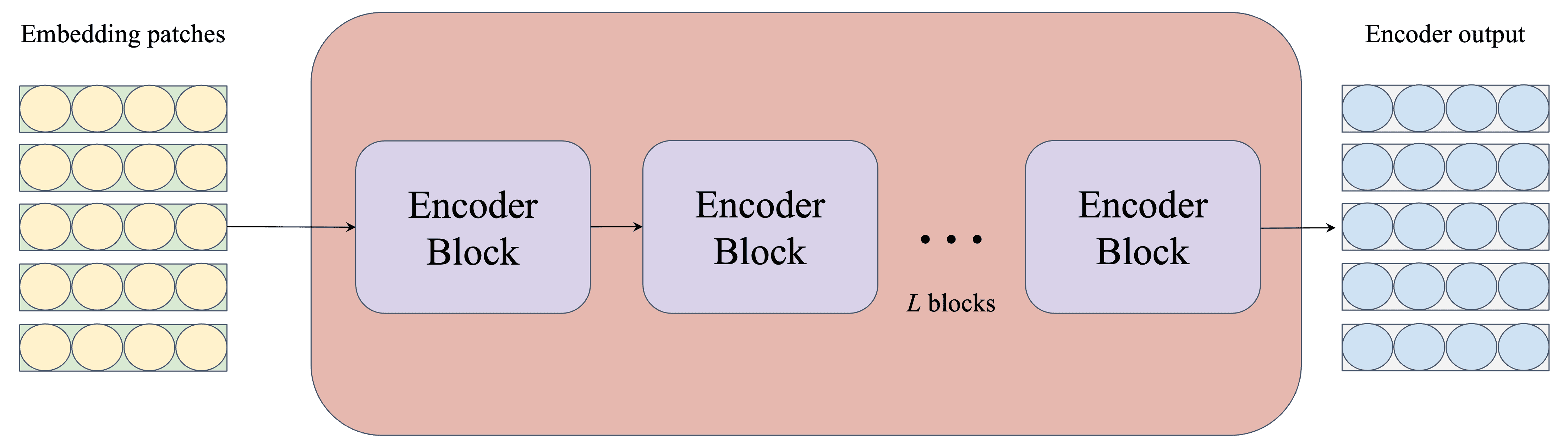 Hình 10: Transformer Encoder hoàn chỉnh. Bên trong bao gồm một số lượng L các Encoder Block.
Hình 10: Transformer Encoder hoàn chỉnh. Bên trong bao gồm một số lượng L các Encoder Block.
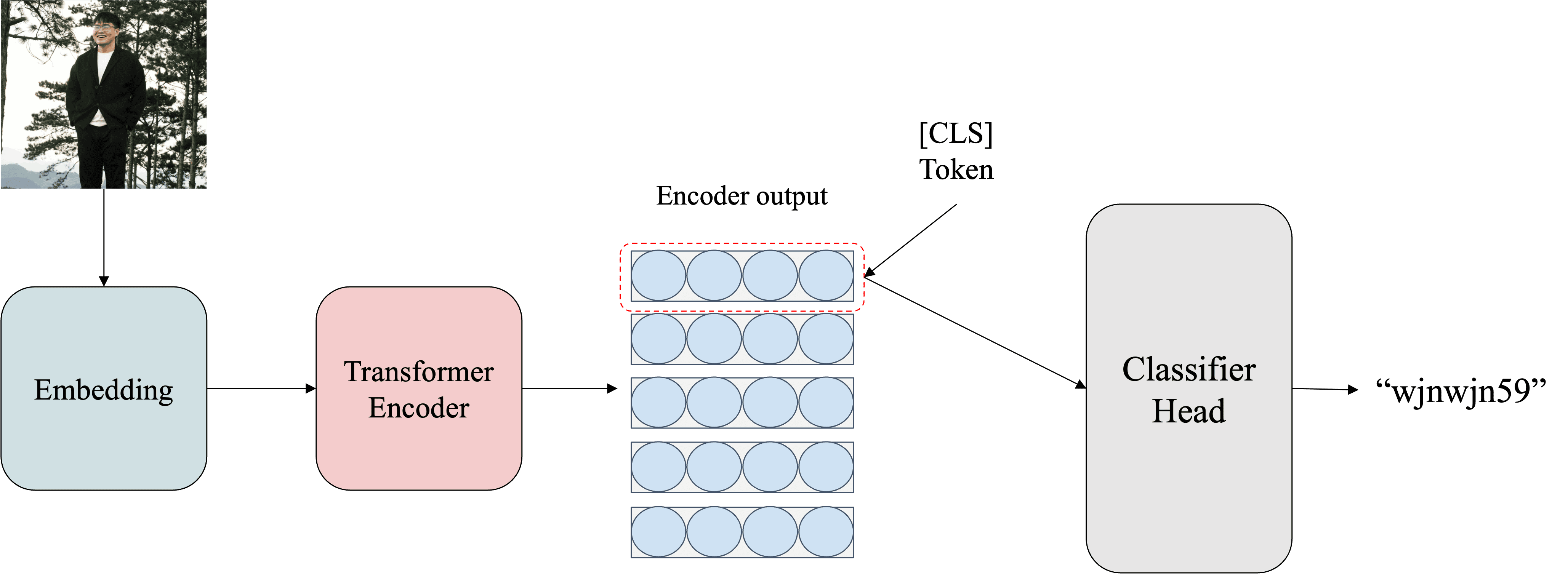 Hình 11: Từ ảnh đầu vào đến giá trị dự đoán nhận được từ ViT.
Hình 11: Từ ảnh đầu vào đến giá trị dự đoán nhận được từ ViT.



